I’m writing these notes a few days before my talk “Software Design and the Physics of Software” at DDD EU (January 29th). The idea is to put them online the night before or the same morning.
In the talk I’ll be hinting at the connection between the notion of friction and the power law distribution in function size that has been observed in many projects. The intent of these notes is to:
- explain that connection
- connect the dots with a previous note, on -ilities as potential
- put some science back in software design
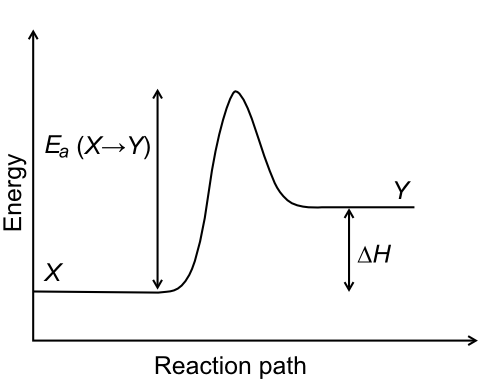
Let’s start at the beginning. In my presentation, I describe the notion of friction in the artifact space, as a force resisting movement. So if you move code from the bulk (body) of a function into a new function, you need to do some work (partially hidden by refactoring tools if you use any) and part of that work is just friction, and goes in counterbalancing resisting forces (that I’ll describe in details in the talk).
In a previous note, I’ve also proposed that many -ilities represent a potential; for instance, reusability is the potential to be reused. The notion of potential also applies in the physical world, of course. When you push an object up a slope, part of the work you do is lost (to friction) and part goes into potential energy.
It would be appropriate to conclude, therefore, that unless all the work we do to move code into a new function is wasted, code moved into a new function keeps some of that energy, in the form of a potential. In fact, once you move code into a new function, you now have the potential to call it from multiple places, a mild form of reusability, or to compose it with something else, etc.
Of course, at this stage we could still say that all this stuff is an interesting hypothesis and nothing more. So why don’t we use the method of science, instead of relying on our rhetorical skills? To quote the great Richard Feynman:
"In general, we look for a new law by the following process. First, we guess it, no, don’t laugh, that’s really true. Then we compute the consequences of the guess, to see what, if this is right, if this law we guess is right, to see what it would imply and then we compare the computation results to nature, or we say compare to experiment or experience, compare it directly with observations to see if it works.
If it disagrees with experiment, it’s wrong. In that simple statement is the key to science. It doesn’t make any difference how beautiful your guess is, it doesn’t matter how smart you are who made the guess, or what his name is… If it disagrees with experiment, it’s wrong. That’s all there is to it.”
So, let’s put some science in software design. We don’t see much, so this could be interesting. Suppose that the hypothesis above is true, that code separated into a new function has more energy than code merged into the body of another function. Then it would follow that adding code to an existing function (say, to handle a special condition or to do further work) takes less energy than creating a new function for that purpose (and having the existing function call into that).
Now, once again, we could just ask around, and collect opinions, possibly skewed by things like “in my preferred language / paradigm that does not happen because I want it to be perfect”. That’s ok if you’re looking for a sociology or even an ethnography of software (which is quite an interesting undertaking anyway) but I’m looking for a physics of software, so let’s push things a bit further.
If that were true, that adding code where we already have some is easier than creating a new function, assuming that on average people will take the path of least resistance (minimize energy / effort), that would be setting up a form of Yule-Simon process, or preferential attachment process, where things tend to go where they already are. Now, we know the consequences of that kind of process. We would end up with a power law distribution in function size.
So here is the thing: we need to check if that is true. If it is not, well, the theory above is wrong. If it turns out to be true, well, as usual in science it’s not a definitive proof that the theory is right, but:
- it adds some confidence in the theory, and we can keep it as a working hypothesis.
- indirectly, it also provides an explanation for the appearance of power laws.
Well, guess what, it turns out that we have a lot of literature exploring the fact that yes, on average, we have a power law distribution in function size. Just too much to add links here in a random note.
What is interesting about the reasoning above is that it provides an important insight: power laws appear when people operate under a more or less conscious minimization of effort. They do not need to appear, and have no magical power of self-regulating the size of your functions like some are proposing. In fact, in my Aspectroid Episode 1, a power law didn’t manifest itself, as I was aiming to contain every artifact to fit into a small page (and I did).
To repeat something I said in my presentation: more observation, less speculation. That would help a lot in software design :-).
In the talk I’ll be hinting at the connection between the notion of friction and the power law distribution in function size that has been observed in many projects. The intent of these notes is to:
- explain that connection
- connect the dots with a previous note, on -ilities as potential
- put some science back in software design
Let’s start at the beginning. In my presentation, I describe the notion of friction in the artifact space, as a force resisting movement. So if you move code from the bulk (body) of a function into a new function, you need to do some work (partially hidden by refactoring tools if you use any) and part of that work is just friction, and goes in counterbalancing resisting forces (that I’ll describe in details in the talk).
In a previous note, I’ve also proposed that many -ilities represent a potential; for instance, reusability is the potential to be reused. The notion of potential also applies in the physical world, of course. When you push an object up a slope, part of the work you do is lost (to friction) and part goes into potential energy.
It would be appropriate to conclude, therefore, that unless all the work we do to move code into a new function is wasted, code moved into a new function keeps some of that energy, in the form of a potential. In fact, once you move code into a new function, you now have the potential to call it from multiple places, a mild form of reusability, or to compose it with something else, etc.
Of course, at this stage we could still say that all this stuff is an interesting hypothesis and nothing more. So why don’t we use the method of science, instead of relying on our rhetorical skills? To quote the great Richard Feynman:
"In general, we look for a new law by the following process. First, we guess it, no, don’t laugh, that’s really true. Then we compute the consequences of the guess, to see what, if this is right, if this law we guess is right, to see what it would imply and then we compare the computation results to nature, or we say compare to experiment or experience, compare it directly with observations to see if it works.
If it disagrees with experiment, it’s wrong. In that simple statement is the key to science. It doesn’t make any difference how beautiful your guess is, it doesn’t matter how smart you are who made the guess, or what his name is… If it disagrees with experiment, it’s wrong. That’s all there is to it.”
So, let’s put some science in software design. We don’t see much, so this could be interesting. Suppose that the hypothesis above is true, that code separated into a new function has more energy than code merged into the body of another function. Then it would follow that adding code to an existing function (say, to handle a special condition or to do further work) takes less energy than creating a new function for that purpose (and having the existing function call into that).
Now, once again, we could just ask around, and collect opinions, possibly skewed by things like “in my preferred language / paradigm that does not happen because I want it to be perfect”. That’s ok if you’re looking for a sociology or even an ethnography of software (which is quite an interesting undertaking anyway) but I’m looking for a physics of software, so let’s push things a bit further.
If that were true, that adding code where we already have some is easier than creating a new function, assuming that on average people will take the path of least resistance (minimize energy / effort), that would be setting up a form of Yule-Simon process, or preferential attachment process, where things tend to go where they already are. Now, we know the consequences of that kind of process. We would end up with a power law distribution in function size.
So here is the thing: we need to check if that is true. If it is not, well, the theory above is wrong. If it turns out to be true, well, as usual in science it’s not a definitive proof that the theory is right, but:
- it adds some confidence in the theory, and we can keep it as a working hypothesis.
- indirectly, it also provides an explanation for the appearance of power laws.
Well, guess what, it turns out that we have a lot of literature exploring the fact that yes, on average, we have a power law distribution in function size. Just too much to add links here in a random note.
What is interesting about the reasoning above is that it provides an important insight: power laws appear when people operate under a more or less conscious minimization of effort. They do not need to appear, and have no magical power of self-regulating the size of your functions like some are proposing. In fact, in my Aspectroid Episode 1, a power law didn’t manifest itself, as I was aiming to contain every artifact to fit into a small page (and I did).
To repeat something I said in my presentation: more observation, less speculation. That would help a lot in software design :-).
 RSS Feed
RSS Feed
